
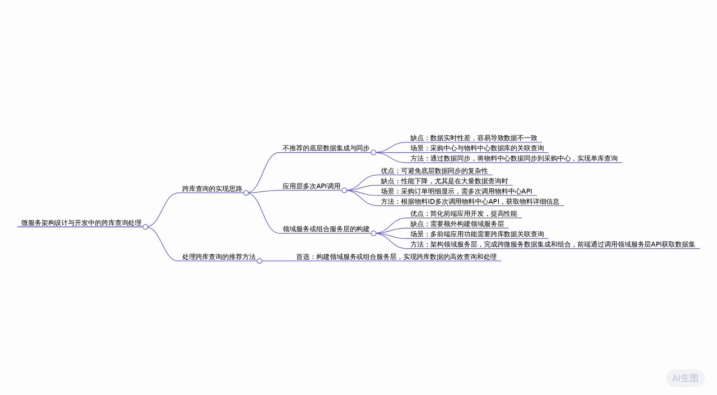
在微服务架构设计和开发中,数据库拆分是一个常见的做法,它有助于提高系统的可扩展性和灵活性。然而,这也带来了一个挑战:当上层应用需要跨库查询时,应该如何实现?本文将探讨三种处理和实现思路,帮助大家解决这一问题。
跨库查询的问题
在微服务架构中,数据库拆分后,原本在一个数据库中的关联查询可能变为跨库查询。这种场景在业务系统中十分常见,比如查看采购订单时,需要同时获取采购订单的基本信息和物料详细信息,而这些信息可能分别存储在采购中心和物料中心两个数据库中。
不推荐的解决方法:底层数据集成与同步
一种直观的解决方法是通过底层的数据集成和数据同步,将跨库查询转换回本地数据库的关联查询。然而,这种方法并不推荐。因为底层的数据集成ETL操作往往带来数据实时性难以满足要求的问题,同时也可能出现数据不一致的情况。这在微服务架构中尤其不可取,因为它违背了微服务独立自治的原则。
推荐的解决方法
多次调用API接口
一种更为推荐的方法是在应用层通过多次调用API接口来实现跨库查询。以采购订单查看功能为例,可以先展示出采购订单的基本信息
,然后对于采购订单的明细信息,根据物料ID多次调用物料中心的API接口获取物料详细信息。最后,在程序中拼装处理这些结果,形
成详细的采购订单明细数据。
然而,这种方法在物料数量较多时可能面临性能问题。因为每次调用API都需要建立数据库连接、关闭数据库连接等一系列操作,这些
操作会耗费大量性能。因此,在实际应用中,需要优化调用方式。
一种优化方法是,将需要展示的物料ID信息拼装成一个字符串,一次传入到API接口中。物料中心的API实现可以根据这些物料ID一次返
回对应的物料详细信息,从而减少数据库操作次数和API调用次数,提高性能。
领域服务层架构
另一种更为优雅且可复用的解决方法是在微服务上架构一个领域服务层或组合服务层。这个服务层负责跨多个微服务和数据库的数据集成和数据组合。前端应用只需要调用领域服务层暴露的API接口,就能获得所需的数据集。
这种方法不仅简化了前端应用的开发,还提高了系统的可维护性和可扩展性。因为领域服务层可以封装复杂的业务逻辑和数据集成逻辑,使得前端应用更加专注于用户界面的实现和业务逻辑的调用。
结语
在微服务设计开发中,数据库拆分后的跨库查询是一个需要认真考虑的问题。本文探讨了三种处理和实现思路,包括不推荐的底层数据集成与同步方法,以及推荐的多次调用API接口方法和领域服务层架构方法。通过合理选择和优化实现方式,我们可以有效解决跨库查询问题,提高系统的性能和可维护性。